一、deepseek本地部署
前提是你的电脑硬件有这个能力以4090显卡设备举例,内存空间24gb ,可以部署32b的deepseek-r1模型
我们本地部署的大模型都不是DeepSeek,而是蒸馏后的模型,想要部署真实的r1或者v3,一般都是企业级的应用了 首先下载蒸馏模型,Ollama 是一个轻量级的本地AI模型运行框架,可在本地运行各种开源大语言模型(如Llama、Mistral等) https://ollama.com/
- 下载ollama平台 · ollama是一个用于本地运行和管理大语言模型(LLM)的工具。
- 配置环境变量 OLLAMAHOST-0.0.0.0:11434 · 作用:让虚拟机里的RAGFlow能够访问到本机上的 Ollama; · 如果配置后虚拟机无法访问,可能是你的本机防火墙拦截了端口 11434; 不想直接暴露 11434 端口:SSH 端口转发来实现; · 更新完两个环境变量记得重启; OLLAMA_MODELS_自定义位置 I ·作用:ollama 默认会把模型下载到C盘,如果希望下载到其他盘需要进行配置
- 通过ollama下载模型deepseek-r1:1.5b
ollama run deepseek-r1:32b;
 下载安装以后我们就可以在cmd里使用
下载安装以后我们就可以在cmd里使用ollama检查是否安装成功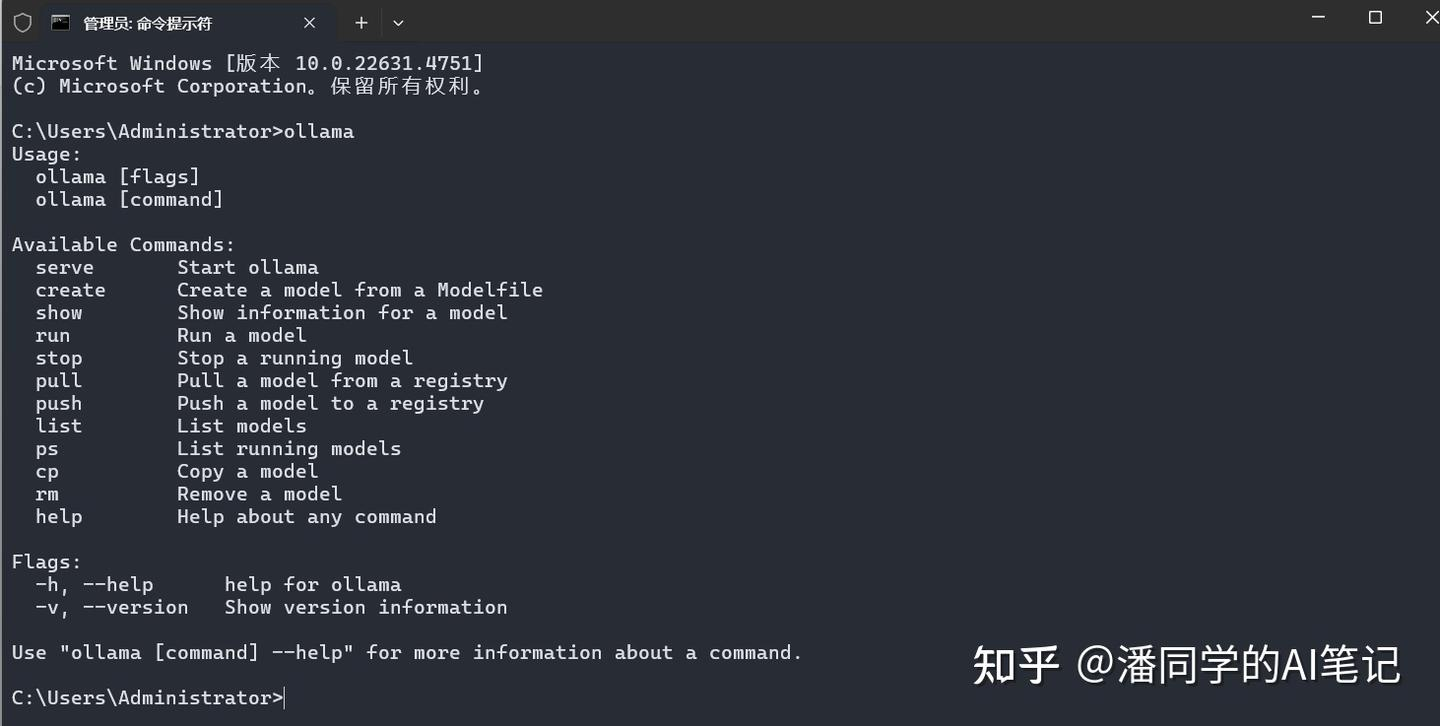 剩下的内容看这篇(主要涉及设置环境变量从而避免模型保存在C盘)
https://zhuanlan.zhihu.com/p/21030210489
剩下的内容看这篇(主要涉及设置环境变量从而避免模型保存在C盘)
https://zhuanlan.zhihu.com/p/21030210489
ollama run deepseek-r1:32b运行模型(首次是下载模型)
二、RAG和微调(建立个人知识库)
1、为什么要使用RAG技术?**大模型的幻觉问题;**RAG和模型微调的区别?
微调技术和RAG技术: 微调:在已有的预训练模型基础上,再结合特定任务的数据集进一步对其进行训练,使得模型在这一领域中表现更好(考前复习); RAG: 在生成回答之前,通过信息检索从外部知识库中查找与问题相关的知识,增强生成过程中的信息来源,从而提升生成的质量和准确性(考试带小抄)。 ·共同点:都是为了赋予模型某个领域的特定知识,解决大模型的幻觉问题。 , RAG (Retrieval-Augmented Generation)的原理: · 检索 (Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容。(找小抄与考试相关点) 增强 (Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。然后再传给生成模型(也就是Deepseek) ;(小抄加自己的yy能力) 生成 (Generation) : 生成模型基于增强后的输入生成最终的回答。由于这一回答参考了外部知识库中的内容,因此更加准确可读。
2、什么是Embedding?为什么除了DeepSeek、RAGFlow外我还需要“Embedding模型”?
· 检索 (Retrieval) 的详细过程: · 准备外部知识库:外部知识库可能来自本地的文件、搜索引擎结果、API 等等。 ·通过 Embedding (嵌入)模型,对知识库文件进行解析:Embedding 的主要作用是将自然语言转化为机器可以理解的高维向量,并且通过这一过程捕获到文本背后的语义信息(比如不同文本之间的相似度关系); ·通过 Embedding(嵌入)模型,对用户的提问进行处理:用户的输入同样会经过嵌入(Embedding)处理,生成一个高维向量。 · 拿用户的提问去匹配本地知识库:使用这个用户输入生成的这个高纬向量,去查询知识库中相关的文档片段。在这个过程中,系统会利用某些相似度度量(如余弦相似度)去判断相似度。 · 模型的分类:Chat模型、Embedding模型; ·简而言之:Embedding模型是用来对你上传的附件进行解析的;
3、RAGflow
- 下载RAGflow源代码https://github.com/infiniflow/ragflow
- 下载Docker · Docker 镜像是一个封装好的环境,包含了所有运行 RAGFlow 所需的依赖、库和配置。 ·如果安装遇到踩坑,可以自行搜索一下报错或者问一下gpt;如果镜像拉不下来,试试修改docker的镜像源;
3、下载好rag的源代码以及docker以后, 解压好的rag源代码里找到docker文件夹修改配置!!! (不修改就会默认下载轻量版本的ragflow,slim(轻量)没有embedding模型,这就需要自己部署,此过程与ollama类似,要么就是调用开源的embedding模型,相对这两种方法比较复杂)
修改步骤:
1、记事本打开F:\ragflow-main\docker.env,注释
RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.0-slim(84行)
2、取消注释# RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.0
3、在C:\Windows\System32\cmd.exe文件目录下输入cmd,运行下面这行命令,就会帮我们自动下载ragflow的镜像,并且启动服务
docker compose -f docker-compose.yml up -d
docker compose -f docker-compose.yml down -v #停止服务在文件夹路径下,框里输入cmd+enter 然后就出现问题了 解决办法是配置docker的C:\Users\1.dockerdaemon.josn文件
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"registry-mirrors": [
"https://docker-0.unsee.tech",
"https://docker-cf.registry.cyou",
"https://docker.1panel.live"
]
}终于解决了这个问题!!!
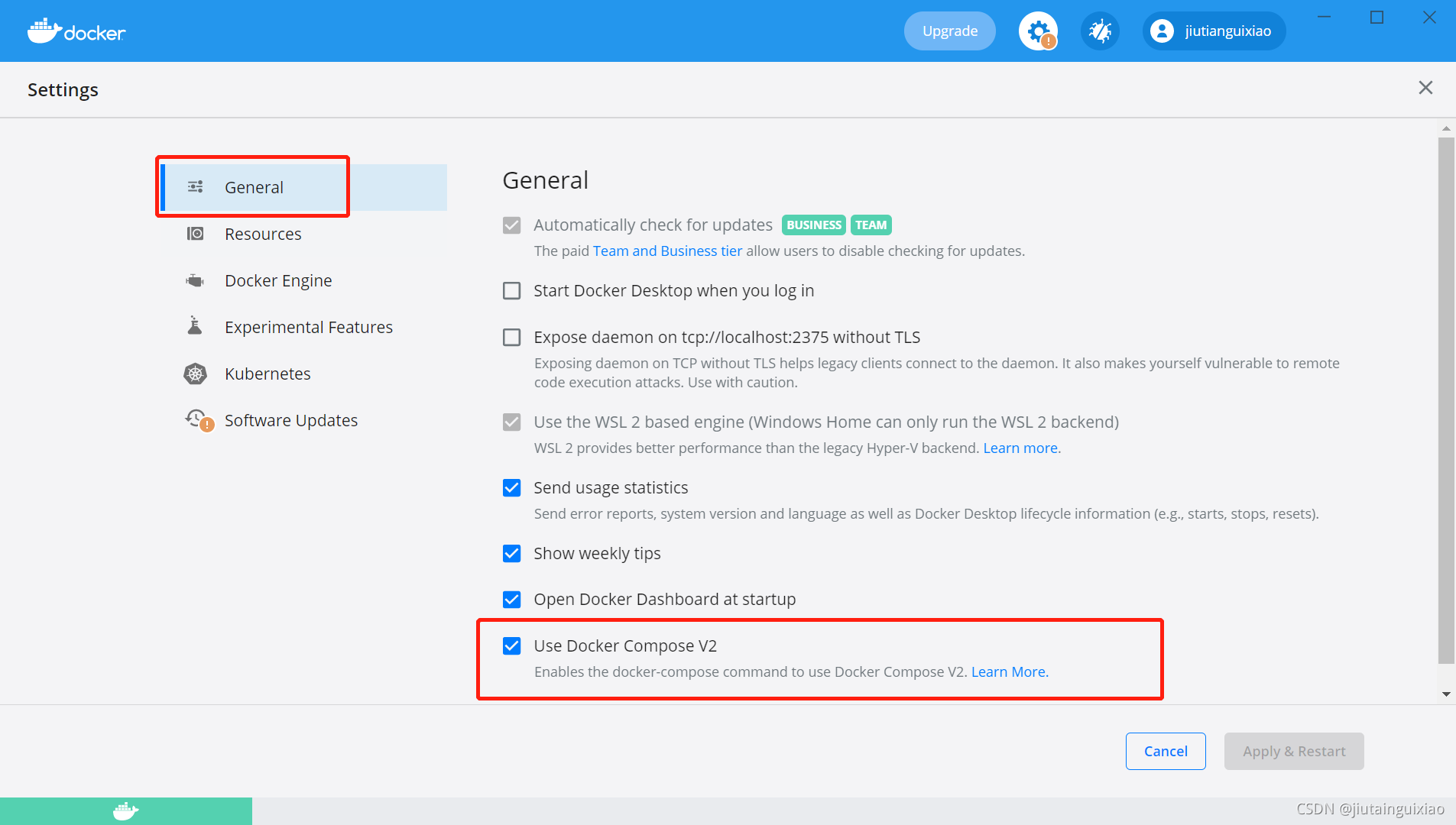
但又报错了,解决:在Docker客户端设置里面General里面将 Use Docker Compose V2勾上即可,重启Docker
error during connect: Post "http://%2F%2F.%2Fpipe%2FdockerDesktopLinuxEngine/v1.47/containers/create?name=ragflow-mysql": EOF
又报错,# 解决Windows Docker容器端口映射问- Ports are not available: exposing port bind: An attempt was made to access 重启WinNAT服务:通过停止并重新启动WinNAT服务,可以解决一些临时的网络配置问题或重置网络状态。
net stop winnat // 停止WinNAT服务
net start winnat // 重新启动WinNAT服务至此,全部问题解决!!!!
网址输入localhost:80,看到下面这个页面就意味着RAGFlow部署成功!
3.在RAGflow中构建个人知识库并实现基于个人知识库的对话问答,
- docker成功启动后,浏览器输入localhost:80来访问RAGFlow;
2.在“模型提供商”中添加我们本地部署的 deepseek-r1:32b 模型;
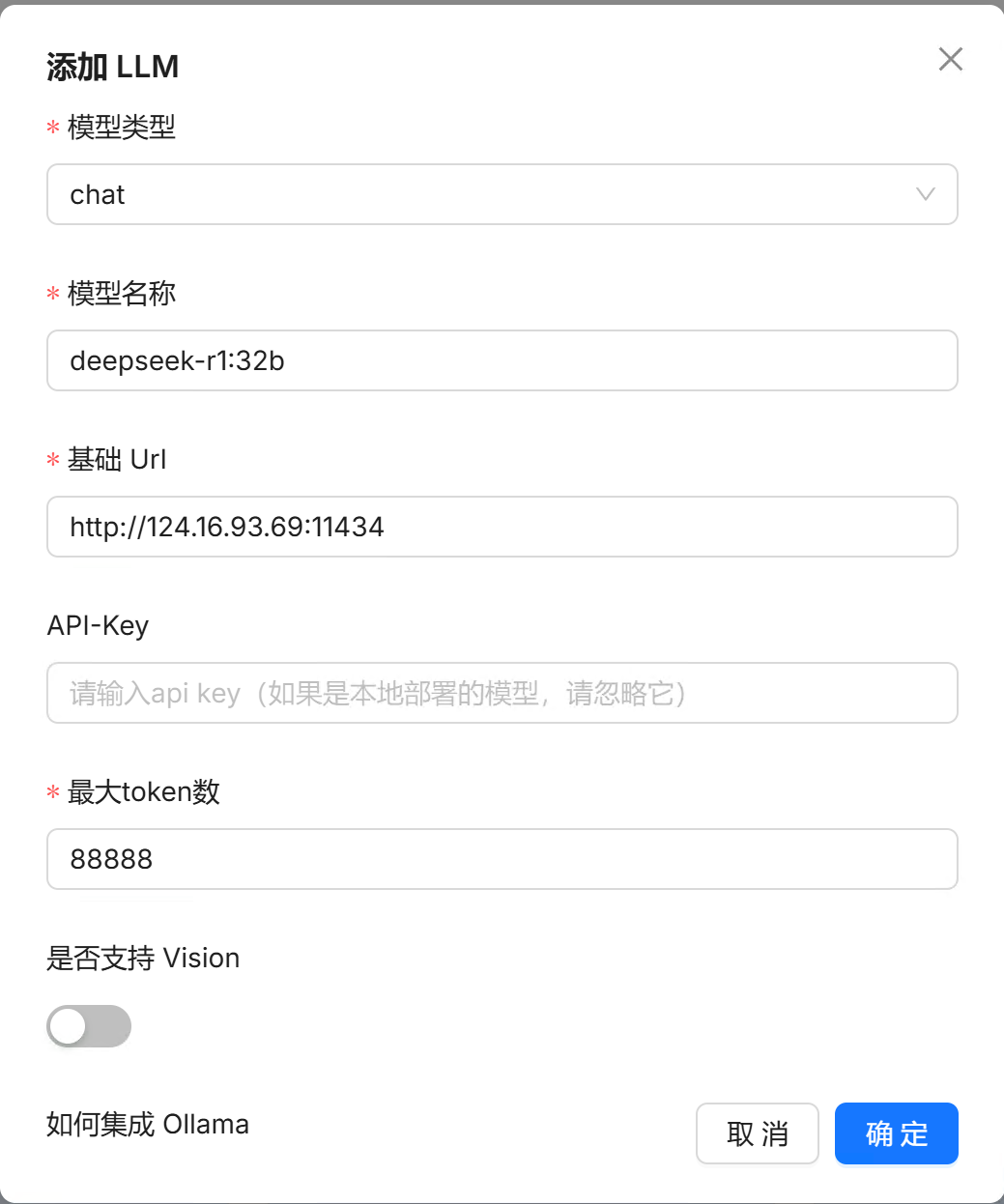
 3.在“系统模型设置”中配置Chat模型(deepseek-r1:32b) 和Embedding模型(用RAGFlow自带的即可) ;
3.在“系统模型设置”中配置Chat模型(deepseek-r1:32b) 和Embedding模型(用RAGFlow自带的即可) ;
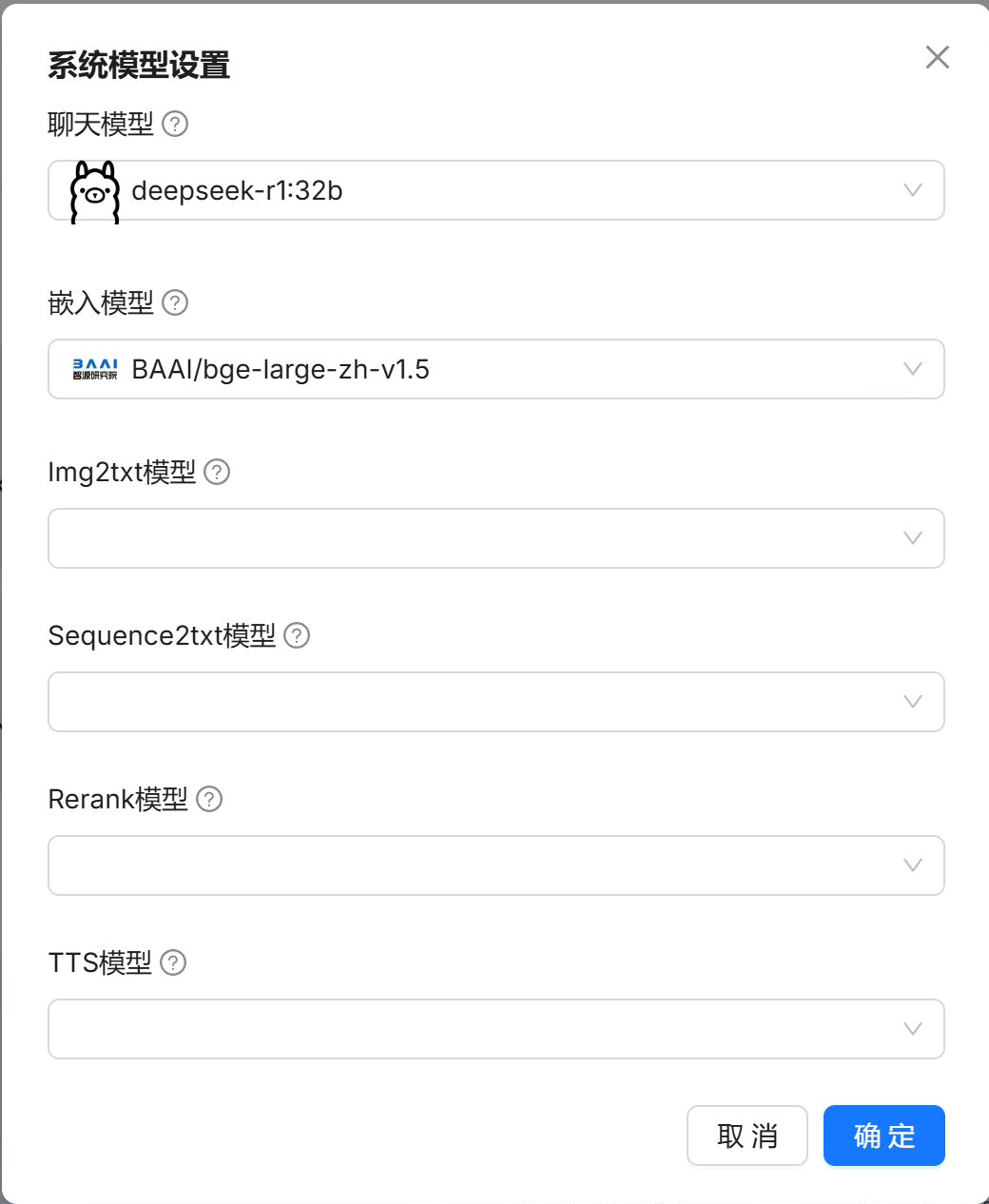
- 创建知识库,上传文件,解析文件;
- 创建聊天助手 (注意prompt和tokens的配置); 6.开始对话;
最终可能会遇到的问题,知识库数据集文件解析失败
首先停止所有正在运行的容器 修改F:\ragflow-main\docker.env 2处 第一处:前面找 ,将elasticsearch改为infinity
# Available options:
# - `elasticsearch` (default)
# - `infinity` (https://github.com/infiniflow/infinity)
DOC_ENGINE=${DOC_ENGINE:-infinity} #这里第二处:第二行取消注释
# Uncomment the following line if you have limited access to huggingface.co:
HF_ENDPOINT=https://hf-mirror.com再运行容器
docker compose -f docker-compose.yml up -d #运行容器
docker compose -f docker-compose.yml down -v #停止运行容器还是用不了,问题的解决方法可能需要
 或者当出现这样的问题
error - Ports are not available: exposing port TCP 0.0.0.0:63791 -> 0.0.0.0:0: listen tcp 0.0.0.0:63791: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
下面是解决方法:
解决Windows Docker容器端口映射问- Ports are not available: exposing port bind: An attempt was made to access-CSDN博客
或者当出现这样的问题
error - Ports are not available: exposing port TCP 0.0.0.0:63791 -> 0.0.0.0:0: listen tcp 0.0.0.0:63791: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
下面是解决方法:
解决Windows Docker容器端口映射问- Ports are not available: exposing port bind: An attempt was made to access-CSDN博客
打开zotero,选中条目,点击文件,导出pdf